

To reference the dataset, please use the following citation:
@article{douze:hal-01162603,
TITLE = {{Circulant temporal encoding for video retrieval and temporal alignment}},
AUTHOR = {Douze, Matthijs and Revaud, J{\'e}r{\^o}me and Verbeek, Jakob and J{\'e}gou, Herv{\'e} and Schmid, Cordelia},
URL = {https://hal.inria.fr/hal-01162603},
JOURNAL = {{International Journal of Computer Vision}},
PUBLISHER = {{Springer Verlag}},
YEAR = {2016},
PDF = {https://hal.inria.fr/hal-01162603/file/paper.pdf},
}
This table sums up the provided data for the datasets:
| Climbing | Madonna | |
|---|---|---|
| Videos | climbing/ | madonna_align_ids.txt |
| ground-truth | gt_climbing.align | gt_madonna.align |
| SIFT descriptors | climbing_sift/ | madonna_sift/ |
| HOF descriptors | climbing_hof/ | madonna_hof/ |
| SIFT align result | found_climbing_sift.align | found_madonna_sift.align |
| HOF align result | found_climbing_hof.align | found_madonna_hof.align |
The Climbing and Madonna datasets contain 89 and 163 videos respectively.
The descriptors and videos are in a directory structure. The whole directory can be retrieved with eg. wget -r http://pascal.inrialpes.fr/data2/evve/videos_align/climbing/.
The descriptors are provided as matrices in the .fvecs file format, one column per frame (at 15 fps) and 1024D per descriptor. The 1024 dimensions are in decreasing order of the PCA components. To use them: keep d <= 1024 dimensions and L2 normalize, then the dot product is a reasonable comparison metric. Note that there are not exactly the same number of frames in HOF and SIFT because of different video decoders.
Each directory corresponds to one of the cameras that were used. Within each directory, the alphabetical order gives the ordering of videos. All videos were converted to a same codec from widely diverging file types. If you are interested in the original files, contact us.
mdna+rome+2012/UJiQE4hEtio 523.08 544.81 -521.30 18 0Where:
mdna+rome+2012/UJiQE4hEtio: ID of the video clip
523.08: starting timestamp of the segment in the video (seconds)
544.81: ending timestamp
-521.30: offset of the video clip in the global alignment, ie. on a global timeline, the segment will play from -521.30 + 523.08 to -521.30 + 544.81
18: (optional) line index, for visualization
0: (optional) group index, also for visualization
The alignment precision is at least 0.5 s, in reality it is a lot better for most clips.
There are additional videos in both Climbing and in Madonna (and additional unannotated footage in the latter). This data is not taken into account during evaluation.
python eval_align_pairwise.py result_file.align groundtruth_file.alignIf segments of a video overlap, the script rejects it, but all possible segments of a video do not need to appear in the file.
The ground-truth alignment has the same format. To compute the maximum possible score (PAS for groundtruth), just run the script on the grountruth file.
NB that for climbing the PAS score is not exactly 108 because of alignment inaccuracies that translate in incomplete overlaps.
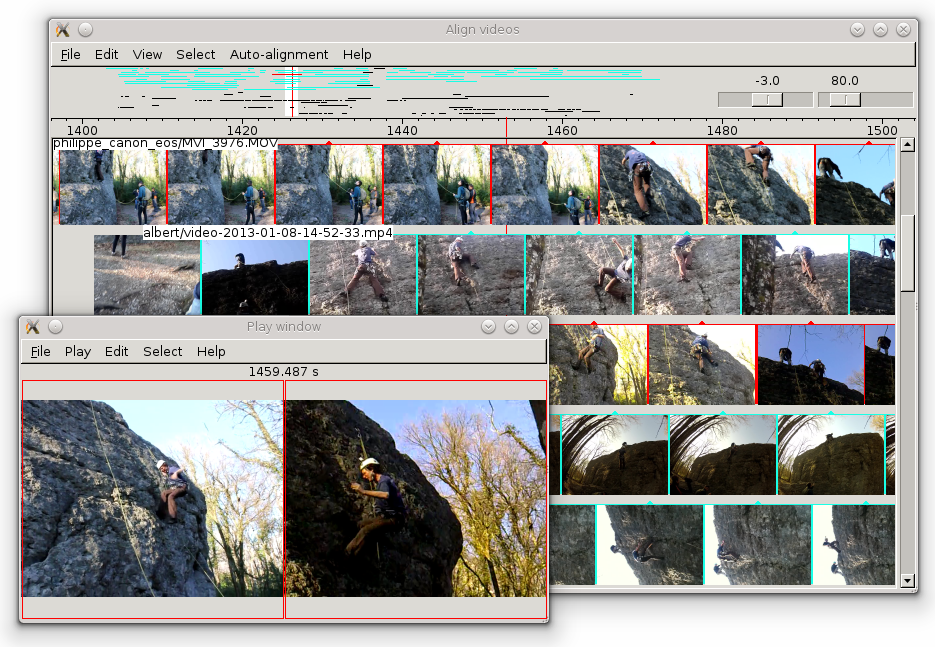
At each time step, all aligned video frames are laid out together in a joint visualization. In this way, the quality of the temporal alignment is directly visible. The grouping of the videos, their alignment as well as the layout of the output is completely automatic. We show hereafter a few interesting examples from Madonna and other videos from the EVVE dataset.
An example from the Madonna dataset. Many people have filmed the concert with their mobile phones, and posted the result on Youtube (some videos are duplicates): vid1, vid2.
Eruptions of the Strokkur geyser are aligned temporally. Some of them show slight misalignments, due to the varying aspect of the geyser: vid.
Universal Studio's Jurassic Park attraction. This group of videos covers almost all of the ride through the Jurassic Park attraction in Universal Studios. vid.
The descriptors and annotations are free.
For any question, remark, bug report, contact matthijs dot douze at inria dot fr